9 Technologies
Technologies arranged by their main goal.
fac n = product [1..n]There once was a man, an engineer by trade, who taught his son to always seek the right tool for the job 19. Here we discuss technologies available to the programmer and how they influence our ability to make, adapt and maintain.
9.1 Bash: Get improvement suggestions for your code
Put this at the top of each script to catch a lot of common errors 20:
set -o errexit; set -o pipefail; set -o nounset;9.2 Bash: Manage and interconnect programs
This tutorial encourages a modular approach to constructing a script. Make note of and collect “boilerplate” code snippets that might be useful in future scripts. Eventually you will build quite an extensive library of nifty routines. As an example, the following script prolog tests whether the script has been invoked with the correct number of parameters.
E_WRONG_ARGS=85
script_parameters="-a -h -m -z"
# -a = all, -h = help, etc.
if [ $# -ne $Number_of_expected_args ]
then
echo "Usage: `basename $0` $script_parameters"
# `basename $0` is the script's filename.
exit $E_WRONG_ARGS
fiMany times, you will write a script that carries out one particular task. The first script in this chapter is an example. Later, it might occur to you to generalize the script to do other, similar tasks. Replacing the literal (“hard-wired”) constants by variables is a step in that direction, as is replacing repetitive code blocks by functions.
Kill all child processes of the current shell: pkill -P $$.
9.2.1 Basic script architecture
References:
A well written script would detect if it was running with the right permissions and not call sudo at all, but there’s a lot of bad scripts.
– Stephen Harris, StackExchange Unix
The script architecture presented here should rather be used in its elements than as a whole. Usually, the cost of adapting the template in its entirety to the needs of the problem at hand requires more time and effort than writing the script from scratch.
#!/usr/bin/env bash
log() {
mkdir log
exec 1>>log/output.log
exec 2>>log/errors.log
}
# Enter strict mode.
set -euo pipefail
# When set, patterns which fail to match filenames during filename expansion
# result in an expansion error.
shopt -s failglob
location=$(readlink -f "$0")
install_dir=$(readlink -f $(dirname $location))
# set -o xtrace
do_stuff() {
echo Doing stuff...
}
list_functions() {
# List all functions found in this file.
# Based on the ideas of Glenn Jackman,
# https://stackoverflow.com
# /a/5868245
typeset -f | awk '/ \(\) $/ && !/^main / {print $1}'
}
ensure_root() {
# Request root privileges.
if [[ $EUID -ne 0 ]] ; then
echo "This script must be run as root." ;
exit 1;
else
proceed
fi
}
show_help() {
printf "Usage: $0 <function_to_call>\n"
echo "= Available functions:"
list_functions
}
main() {
show_help
}
check_command() {
# Verify that the command exists and is a function,
# Credit: that other guy, Stack Overflow
# Check if the function exists (bash specific)
if declare -f "$1" > /dev/null
then
# call arguments verbatim
"$@"
else
# Show a helpful error
echo "'$1' is not a known function name" >&2
exit 1
fi
}
call_directly() {
if [[ $# -gt 0 ]] ; then
"$@"
else
return 1
fi
}
(call_directly "$@" && exit 0) || main "$@"In particular:
Your bash scripts will be more robust, reliable and maintainable if you start them like this:
#!/bin/bash
set -euo pipefail
IFS=$'\n\t'Source: Aaron Maxwell, redsymbol.net
Expanded, more understandable form of the rules (shebang omitted for clarity):
set -o errexit; set -o pipefail; set -o nounset; set -o xtrace;
IFS=$'\n\t'With added line numbers for situations where it fails:
set -o errexit; set -o pipefail; set -o nounset; set -o xtrace;
trap 's=$?; echo "$0: Error on line "$LINENO": $BASH_COMMAND"; exit $s' ERR
IFS=$'\n\t'Source: Oliver Gondza, https://olivergondza.github.io/2019/10/01/bash-strict-mode.html
9.2.2 Getting help
Try apropos first, or man -k (which requires mandb to be running), if you don’t know exactly which command to read about with man. Then man, pinfo (preferred) or info 21.
If you need help to a particuar command, command --help is usually the way to go, sometimes that is shortened to command -h instead.
Additional help for some commands can be found at /usr/share/doc.
More: Linux Fundamentals video playlist by Sander van Vugt, Pearson IT Certification 2019
Zeal Docs is a good program to have on hand in case offline operation becomes necessary for a while.
Examples of some Linux commands: curl cheat.sh 22.
Also in Bash, help <command> works, as in help help.
If you feel you have to refer to online resources to get help, you can make
that experience less engaging by using qutebrowser. It allows you to browse
the Web using solely Vim-style keyboard controls.
One of the things that can really make or break a project for me is how its developers behave towards the users. The developer of this project is a really upstanding, responsive, kind human being. I think his project deserves all the attention it can get.
I have used qutebrowser as my primary browser on Linux for years. I have no complaints. In fact, qutebrowser runs smoothly on some of my older machines where Firefox struggles to run.
– YC News
9.2.3 History search
Create a file named ~/.inputrc and fill it with the following:
"\e[A": history-search-backward
"\e[B": history-search-forwardThis allows you to search through your history using the up and down arrows. Type “cd” and press the up arrow and you’ll search through everything in your history that starts with “cd”.
Source: Jude Robinson, The single most useful thing in bash
9.2.5 Set path for new panes to current tab
Type [Ctrl]+[b], and then:
:attach-session -c "#{pane_current_path}"9.2.6 Splitting windows
See Tmux: Ham Vocke’s Introductory Tutorial.
If you experience problems with colors in Vim, you may add the following line
to your ~/.tmux.conf:
set -g default-terminal "screen-256color"In ~/.vimrc, you need to explicitly define the background color:
set background=dark9.2.7 Connecting to Wi-Fi
You can use the following script to connect to the network in a way that will leave your connection saved on the list of connections.
After that, only the last command from the connect_wifi function will be
needed to re-connect to the network.
#!/usr/bin/env bash
name="SSID"
pass="password"
connect_wifi() {
sudo apt install -y network-manager
sudo service network-manager start
service network-manager status
nmcli d wifi list
echo "If the next step fails, reboot the system."
sudo nmcli dev wifi connect "$name" password "$pass"
sudo nmcli con down id 2.4G-Vectra-WiFi-50BCB8
sudo nmcli con up id 2.4G-Vectra-WiFi-50BCB8
}
connect_wifi9.2.8 Cat
{ foo; bar; cat mumble; baz } | whatever
– http://porkmail.org/era/unix/award.html
Using cat on a single file to view it from the command line is a valid use of cat (but you might be better off if you get accustomed to using less for this instead).
– porkmail.org/era/unix/award.html
For example, to format a one-line dict output from Python as JSON, one can do:
$ cat file_with_single_quotes | tr "'" '"' | jq ...Could this be simplified? Yes!
$ tr "'" '"' < file_with_single_quotes | jq ...9.2.9 Show an image
You can show an image “in Bash”. Actually, it is shown in the frame buffer. The command is:
sudo fbi -T <terminal_number> <image_file>You need sudo to give the command direct access to the frame buffer.
Example using TTY2:
sudo fbi -T 2 img.jpg9.2.10 Redirect command output
Redirections can be set along the function definition, eg.:
f () { echo something; } > logNow no explicit redirections are needed by the function calls.
$ fSource: https://unix.stackexchange.com/questions/313256/why-write-an-entire-bash-script-in-functions
9.2.11 List file users
See fuser. Example: fuser -v db.sqlite3. More: https://stackoverflow.com/questions/3172929/operationalerror-database-is-locked.
9.2.12 Time a command
This script outputs a single value in seconds of wall clock time. It is designed to simplify repeated measurement.
It once took hours of trial-and-error analysis and Internet searching to obtain this result both with Bash and Zsh, and then it was needed again and was again taking too much time. For this reason the ready script ends up here.
#!/usr/bin/env bash
# The result is in seconds of wall time.
#
# Example:
#
# > time_this ls
# 0.01
time_this() {
run_this="$1"
# Time wall-clock program execution time.
/usr/bin/time -f "%e" bash -c "$run_this > /dev/null"
# Round result to 1/100 of a second.
t=echo ${output} | awk '{printf("%d\n",$0+=$0<0?-0.5:0.5)}'
printf "$t"
}
time_this "$1"9.2.13 Print file contents into a pipeline
We could use cat. This would be considered its misuse by some. An alternative
would be to use the redirection operator as presented below.
<file ./command --argsOr:
./command <file --argsBoth have been reported to work fine in Bash and Zsh.
Such approach resembles a little the “point-free” style of programming.
Source: news.ycombinator.com
9.2.14 Conditional variable set
This technique allows for a variable to be assigned a value if another variable is either empty or is undefined.
name=${1:-default_name}9.2.16 Enable command tab completion
To enable tab-completion, refer to Kyle Bak:
# Bash
complete -F <completion_function> notes
# Zsh
compctl -K <completion_function> notes9.2.17 Run function in a sub-shell by default
To spawn the function in a subshell rather than execute it in the current environment, replace the usual code-block braces with normal braces 23:
Turning this:
function name () {
# Code here
}into this:
function name () (
# Code here
)9.2.18 Literate shell scripting
- Install Basher:
git clone https://github.com/basherpm/basher.git ~/.basher - Add Basher to
PATH:echo 'export PATH="$HOME/.basher/bin:$PATH"' >> ~/.profile - Add Basher
initto shell startup:echo 'eval "$(basher init -)"' >> ~/.profile. - Re-login to shell,
- Run
basher updateto update Basher, - Run
basher install bashup/mdsh
9.2.19 Unit-testing Bash scripts
One option is BATS (Bash Automated Testing Suite). An exemplary tutorial is here.
Other options are listed here.
To install BATS automatically on Ubuntu and similar operating systems, use the following script:
#!/usr/bin/env bash
bats_version=1.2.1
install_all() {
install_bats() {
archive=v"$bats_version".tar.gz
unpacked_dir=bats-core-"$bats_version"
wget -cq https://github.com/bats-core/bats-core/archive/"$archive" \
&& tar zxf "$archive" \
&& rm "$archive" \
&& cd "$unpacked_dir" \
&& ./install.sh ~/.local \
&& cd - > /dev/null \
&& rm -rf "$unpacked_dir"
}
install_bats
}
check_bats() {
if [[ "$(bats --version)" == "Bats $bats_version" ]]; then
echo "Bats OK"
else
echo "Bats unavailable or version does not match."
fi
}
manage_install() {
show_help() {
echo "Usage: $0 [--install-all | --help]"
echo "Target platform: Linux, tested on Ubuntu 18.04."
}
temp_dir="$(mktemp -d)"
## Remove all temp files on exit and sigint
trap "rm -rf $temp_dir" EXIT SIGINT
if [[ $# -lt 1 ]]; then
check_bats
elif [[ "$1" == "--help" ]]; then
show_help
elif [[ "$1" == "--install-all" ]]; then
cd "$temp_dir" && install_all
else
show_help
fi
}
manage_install "$@"9.2.20 Returning a parameter from a lambda function
export CLUSTER_IP=$(microk8s.kubectl get svc/nginx -o go-template='{{(index .spec.clusterIP)}}')
echo CLUSTER_IP=$CLUSTER_IP
lynx $CLUSTER_IP:80Example comes from Katacoda. It was found here.
9.2.21 Change a string in a file
Edit file in place - filter: sed -i 's/STRING_TO_REPLACE/STRING_TO_REPLACE_IT/g' filename
9.2.23 Design complex text pipelines in a fast feedback loop
up is the Ultimate Plumber, a tool for writing Linux pipes in a terminal-based UI interactively, with instant live preview of command results.
– up
The syntax for the conditional is: if ! command ; then ... ; fi. [ is itself a command, and it’s not needed in this case.
Source: Keith Thompson, https://unix.stackexchange.com/a/22728/309163
9.2.24 Find duplicate files
Tool named duff reports on duplicate files, via a SHA1 hash of the contents,
recursively. For alternatives, see 24.
9.2.25 Clean up a string in the clipboard
Xclip manipulates the clipboard from the command line. Sed edits strings on-the-fly.
xclip -o | sed 's///g' | xclip -i
9.2.26 Tunnel via SSH
Run an HTTP server on remote node and browse through local web browser:
- Remote:
python2 -m SimpleHTTPServer 25000orpython3 -m http.server 25000, - Local:
ssh-L 8000:localhost:25000 id@remote-N - Open browser on local and navigate to http://localhost:8000
Credit: Ketan M., “SSH Tunneling Example”, Linux Productivity Tools
9.3 Bash: Easily migrate your user config
Fabien “StreakyCobra” Dubosson [^fabien] uses the following setup:
git init --bare $HOME/.myconf
alias config='/usr/bin/git --git-dir=$HOME/.myconf/ --work-tree=$HOME'
config config status.showUntrackedFiles noWhere directory ~/.myconf is a “bare” Git repository.
Then any file within the home folder can be versioned with Bash commands like:
config status
config add .vimrc
config commit -m "Add vimrc"
config add .config/redshift.conf
config commit -m "Add redshift config"
config pushThis approach has been adopted by Jeremy Howard as the recommended way to configure workstations for Fast.AI 25.
9.5 Git: Track code changes
9.5.1 Quick demo / Getting started
- https://git-scm.com/book/pl/v1/Podstawy-Gita-Pierwsze-repozytorium-Gita
- https://www.flynerd.pl/2018/02/github-dla-zielonych-pierwsze-repozytorium.html
To upload a repo to a remote server, register on GitHub.com, then go to GitLab.com and use the option “Login with GitHub” there.
Starting with GitHub gives you the advantage of having an account there and therefore being able to contribute to projects there.
Last time I checked, proceeding in reverse order (GitLab -> GitHub) requires creating two separate accounts.
9.5.2 Tracking changes in files
Track an existing directory with GitLab online:
cd existing_folder
git init
git remote add origin <repository_url>
git add .
git commit -m "Initial commit"
git push -u origin master9.5.2.2 Merge several commits as one
git merge --squash <branch_name>
Full tutorial: https://github.com/rotati/wiki/wiki/Git:-Combine-all-messy-commits-into-one-commit-before-merging-to-Master-branch
9.5.3 Reset repo to exactly match the origin branch
git fetch origin
git reset --hard origin/master
# To clean untracked directories and files
git clean -d --forceDiscussion: SO
9.5.3.1 Encrypt secrets in repo
brew install git-crypt
cd repo && git-crypt init
– More
Git-Crypt supports multiple GPG keys and thus enables sharing different secrets with different collaborators! More can be read here.
Export secrets to a new machine:
gpg --export *your key-ID* > path/to/public/key/backup/file
gpg --export-secret-keys *your key-ID* > path/to/secret/key/backup/fileYou can import these files later 26:
gpg --import path/to/public/key/backup/file
gpg --import path/to/secret/key/backup/file9.5.3.2 Remove spare files
git filter-branch --tree-filter 'rm -rf ścieżka_pliku_względem_repozytorium' HEAD
– More: Tutorial
9.5.4 Summarize changes from last tag
You can use the syntax: git shortlog <starting_tag>..HEAD, for example: git shortlog 1.0.0..HEAD.
To automatically start counting changes from the most recent tag, use:
git shortlog $(git describe --tags --abbrev=0)..HEAD
Credit: eis, StackOverflow, https://stackoverflow.com/a/12083016
9.5.5 Find the branch you worked on last
You checked out a few branches to work on your pull requests, also to review coworkers’ code and provide your insightful feedback. You now want to pick up where you left off with some past work. What was that branch named?
$ git branch --sort=-committerdate | headFrom Damian Janowski, https://dimaion.com/tips-for-working-with-git-branches/
9.6 GitLab
9.6.1 Start with CI in GitLab
# GitLab Code Runner
# ==================
#
# More: https://docs.gitlab.com/
# runner/install/docker.html
gitlab-runner:
image: 'gitlab/gitlab-runner:latest'
restart: always
volumes:
- '/srv/gitlab-runner/config:/etc/gitlab-runner'
- '/var/run/docker.sock:/var/run/docker.sock'Read more: https://docs.gitlab.com/runner/install/docker.html
9.6.2 Establish a remote repo from the local terminal
git push --set-upstream [email protected]:kocielnik/$(git rev-parse --show-toplevel | xargs basename).git $(git rev-parse --abbrev-ref HEAD)Source: https://gitlab.com/help/gitlab-basics/create-project#push-to-create-a-new-project
9.7 Linux
9.7.2 Development
9.7.2.1 Building
9.7.2.1.1 Make
Setting variables:
Lazy:
VARIABLE = valueImmediate:
`VARIABLE` := valueSet if absent:
VARIABLE ?= valuePackage installation directory prefix: define for easy adjustment between
/usr and /usr/local: PREFIX ?= /usr
More here
9.7.2.1.2 Deb packaging
Sometimes we need a simple way to install a package while ensuring that we will be able to uninstall it some day. The distribution packaging system comes in handy in such situations.
A simple packaging guide for Debian and Ubuntu is available here.
9.7.2.2 Testing
To test software agains Bash I/O, you can use bats.
Consult the BATS file format syntax: man 7 bats. In general, chapter 7 of the
Man pages includes “macro packages and conventions”.
9.7.2.2.1 Create a clean testing environment
Quickly set-up a clean Linux environment in a container.
docker pull ubuntu:xenialordocker pull amd64/node,docker run --name testing_ground --rm -it ubuntu:xenial bashfor a clean Ubuntu, or- or
docker run --name testing_ground --rm -it ubuntu:18.04 bashfor a clean Ubuntu Bionic (newest LTS),
- or
docker run --name testing_ground --rm -it amd64/node bashfor a clean NodeJS container,
- Now we can execute commands inside the container. WARNING: All session data will be lost when upon exiting the container.
9.7.2.2.2 Test scenarios
9.7.2.2.2.1 Test HTTP service availability
To test connectivity with a container, call the following script:
#!/usr/bin/env bash
# Test if visiting the my.service.com page returns a `success` HTTP response code.
printf "Is the GitLab server accessible via HTTPS?: "
res=`curl -w "%{http_code}\n" "https://my.service.com" -s -o /dev/null -L`;
if [ "$res" -eq 200 ] ; then echo "true"; else echo "false"; fi9.7.2.3 Packaging
Cleanly install a Linux package you prepared: If your package has no make uninstall target, issue sudo checkinstall.
Ensure root privileges before make install:
install:
@bash -c "if [[ $EUID -ne 0 ]] ; then \
echo \"This script must be run as root.\" ; \
exit 1; \
else \
cp -r . /usr/local/my_package ; \
fi"A typical incantation to install a source package looks something like this.
[root]# tar -xzvf ${name}.tar.gz
Unpacking ...
[root]# cd ${name}
[root]# more README
[root]# more INSTALL
[root]# ./configure
[root]# make
[root]# make installSource: http://www.control-escape.com/linux/lx-swinstall-tar.html
When using the GNU Autotools— and most other build systems— the default installation location for your new software will be
/usr/local. Which is a good choice as according to the FSH “The /usr/local hierarchy is for use by the system administrator when installing software locally? It needs to be safe from being overwritten when the system software is updated. It may be used for programs and data that are shareable amongst a group of hosts, but not found in /usr.”
– https://itsfoss.com/install-software-from-source-code/
/optis reserved for the installation of add-on application software packages.
9.7.3 Operations
9.7.3.2 System administration
9.7.3.2.1 Managing processes
See PM2 by Alexandres Strzelewicz. We could not get tired of praising it for its usefulness.
9.7.3.2.2 Managing hardware
Check station model: dmidecode | grep -A3 '^System Information'.
Example output:
System Information
Manufacturer: Dell Inc.
Product Name: Precision M47009.7.3.2.3 Configuration
9.7.3.2.3.1 Install a package from source
The standard, UNIX-wide universal way to install a TGZ package after 27:
./configure,make,make install.
If you need to deploy the package over SSH, deployr might be helpful.
9.7.3.2.3.2 Install a package in Ubuntu
Use apt instead of apt-get: Apt is a modern overlay of apt-get and apt-cache. See It’s FOSS.
9.7.3.2.3.6 Replace a configuration line
Replace a line setting with another: awk '/line_string_to_seek_to/{gsub(/previous_value/, "new_value")};{print}' file_name. For example, to substitute my.satpack.eu for localhost, we do the following:
awk '/ws = new WebSocket/{gsub(/8443/, "443")gsub(/localhost/, "my.satpack.eu")};{print}' private/main.js > private/main.js.new && mv private/main.js.new private/main.jsYou can also use sed to modify the line. It should be similarily convenient.
9.7.3.2.3.7 Synchronize two directories
rsync -rtvu --delete source_folder/ destination_folder/
Explained here.
9.7.3.2.3.8 Re-run a program every boot
# modem_connection.service
# To be placed in /lib/systemd/system/ and run as a service.
[Unit]
Description=Modem Connection
After=network.target
StartLimitIntervalSec=0
[Service]
Type=idle
Restart=on-failure
# Define single interval length for service start (10 seconds).
#StartLimitIntervalSec=10
# How many starts in an interval are allowed. This means 1 service start will
# be allowed every 10 seconds.
StartLimitBurst=1
RemainAfterExit=true
User=root
ExecStart=/absolute/command/path
[Install]
WantedBy=multi-user.targetTo install and activate the above file, use the following script:
#!/usr/bin/env bash
# install_service: Install as a system service.
name=modem_connection
unit_file_dest=/lib/systemd/system/$name.service
readonly progname=$(basename $0)
readonly progdir=$(readlink -m $(dirname $0))
readonly args="$@"
install() {
if [[ $EUID -ne 0 ]] ; then
echo \"This script must be run as root.\" ;
exit 1;
else
cp "$progdir/$name.service" "$unit_file_dest"
if [ $? -eq 0 ] ; then
echo "OK"
fi
fi
sudo systemctl enable "$name"
}
state() {
if [ -e "$unit_file_dest" ]; then
echo Service is installed.
exit 0
else
echo Service not present.
exit 1
fi
}
remove() {
if [[ $EUID -ne 0 ]] ; then
echo \"This script must be run as root.\" ;
exit 1;
else
rm -f "$unit_file_dest"
if [ $? -eq 0 ] ; then
echo "OK"
fi
fi
}
# Call function given by the user with arguments they provided:
echo $($@)To disable the service and remove the file, use the following script:
#!/usr/bin/env bash
# disable_service: Disable the service if present.
name=modem_connection
systemctl status "$name" &>/dev/null
if [[ $? -eq 0 ]] ; then
sudo systemctl stop "$name" > /dev/null
sudo systemctl disable "$name" > /dev/null
fi9.7.3.2.4 Users
9.7.3.2.4.1 Generate a random password
The Stanford University password policy requires that you use mixed characters only for passwords under 20 characters in length.
Above that length, you can use any characters you like and - by the mentioned standard - consider your passwords secure!
head /dev/urandom | tr -dc A-Za-z0-9 | head -c 13 ; echo 28
Another way:
randpw() {
< /dev/urandom tr -dc _A-Z-a-z-0-9 | head -c${1:-16};echo;
}Using passphrases:
# > new_memorable_password 5
# StationingMovementsCatwalksOmnivoresPolygamist
new_memorable_password() {
words="${1:-5}"
sep="${2:--}"
LC_ALL=C grep -x '[a-z]*' /usr/share/dict/words \
| shuf --random-source=/dev/urandom -n ${words} \
| paste -sd "$sep" \
| sed -r 's/(^|-)(\w)/\U\2/g'
}Credit: https://unix.stackexchange.com/a/470374
Idea from: xkcd.
9.7.3.2.5 Networking
9.7.3.2.5.1 Flush DNS caches
Tested on Ubuntu:
# Which DNS server reports the entry?
nslookup example.com
dig example.com
# Is local DNS cache enabled? What does it say?
systemd-resolve --statistics
# Flush cache and reload the service.
sudo systemd-resolve --flush-caches
sudo systemctl restart systemd-resolved
# Is local DNS cache clean now?
systemd-resolve --statisticsSource: LinuxHint.com
9.7.3.2.5.2 Fix DNS
Try editing /etc/systemd/resolved.conf, adding your desired DNS server:
Change this:
[Resolve]
#DNS=to this (but use the one you want - this is an example):
[Resolve]
DNS=192.168.1.152after that, restart the service:
service systemd-resolved restartAnd when you check the status you should see
$ systemd-resolve --status
Global
DNS Servers: 192.168.1.152
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpaSource: https://askubuntu.com/questions/973017/wrong-nameserver-set-by-resolvconf-and-networkmanager
9.7.3.2.5.3 Download a large file
aria2c -x 10 -i download_list.txt >/dev/null 2>/dev/null &
In the file download_list.txt, write one URL per line as below:
https://www.example.com/1.mp4
https://www.example.com/2.mp4
https://www.example.com/3.mp4Aria2c was installed when I checked on Ubuntu 18.04. It may be a part of the default configuration of that system.
9.7.3.2.5.4 Change host name
- Edit
/etc/hostnamefile to match needs, - Run
/etc/init.d/hostname.sh startto apply change to the running system. - Edit
/etc/hoststo match your new host name (optional, for cleanliness).
9.7.3.2.5.5 Test network speed from console
curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
Or:
sudo apt install speedtest-cli
speedtest-cliOr:
pip install --user speedtest-cli9.7.3.2.5.6 Nginx: redirect subdomain to a port quickly
server {
listen 80; # Port to redirect
server_name docker.giss.pl; # Queried address
location / {
proxy_pass https://localhost:5001; # Address to point to
}
}See here.
Edit the file /etc/nginx/sites-enabled/default.
What is Nginx in a few sentences?
Nginx is event-based and therefore works differently to Apache. Individual requests are not classified as new work processes (for which all modules have to be loaded), but rather as events. These events are divided into existing work processes, which are maintained by the primary main process. The nginx.conf configuration file defines the number of work processes that ultimately exist, as well as how the server requests (i.e. the events) are divided. You can find them in these files /usr/local/nginx/conf, /etc/nginx or /usr/local/etc/nginx.
9.7.3.2.5.7 Alias a host with a domain name for external use
Set up an external domain name for a host: NoIP.
9.7.3.2.5.9 Review listening interfaces
netstat -a / nmap localhost
Or:
sudo lsof -i
sudo netstat -lptu
sudo netstat -tulpn9.7.3.2.5.10 Find live hosts on your subnet
nmap -sn 192.168.1.1/24
Systems administrators often find this option valuable as well. It can easily be used to count available machines on a network or monitor server availability. This is often called a ping sweep, and is more reliable than pinging the broadcast address because many hosts do not reply to broadcast queries.
9.7.3.2.5.11 List all MAC addresses on subnet
sudo arp-scan --interface=eth0 --localnet
– Peter Mortensen and user 260894, Ask Ubuntu
9.7.3.2.5.12 Edit the SSH welcome message
Edit the file /etc/motd. More on this topic is here.
Change the message into a dynamic one: read in the above article under the section “How to then?”.
9.7.3.2.5.13 Allow a port in Ubuntu
For example, for port 444 issue: ufw allow 444/tcp.
Warning: UFW may not run instead, but in series with iptables. To configure iptables, follow simple instructions here.
To save the rules, issue sudo service iptables save.
9.8 Direnv
When you have a Python project with some dependencies specified, you can either install them globally, or create a virtual environment for the project.
The problem with the first approach is that it may override some packages you already had installed to make other projects work.
The problem with the second approach is that you need to explicitly enter the virtual environment every time you want to run some actions on the project, like starting the test suite.
That is beacuse the dependencies you installed are only visible inside the virtual environment.
Specifically, if you installed PyTest only in the VirtualEnv, you will get an
error if you call pytest outside of the virtual environment.
Direnv is a tool that solves this problem by automatically activating the virtual environment when you enter the project directory, and deactivating it when you leave.
It is very easy to set up. In many cases, you only need to create a file named
.envrc in the project directory with the following content:
layout pythonDirenv aims to be secure by requiring you to explicitly allow the .envrc file
before it will execute it. To allow the file, run direnv allow in the project
directory.
Example config for Python and UV, by Tymoteusz Makowski:
# ~/.config/direnv/direnvrc
layout_uv() {
if [[ ! -d ".venv" ]]; then
log_status "Creating venv with uv..."
uv venv
fi
VIRTUAL_ENV="$(pwd)/.venv"
PATH_add "$VIRTUAL_ENV/bin"
export VIRTUAL_ENV
# Reload on changes to the dependencies.
if [[ -f "uv.lock" ]]; then
watch_file uv.lock
fi
if [[ -f "pyproject.toml" ]]; then
watch_file pyproject.toml
log_status "Syncing dependencies with uv..."
uv sync
fi
}I’ve used direnv for a few years now. Especially combined with Nix, it’s magical how seamlessly you can navigate between very different environments!
Direnv becomes even more versatile when used with Nix:
The thing I want to say is this: nix-direnv is great. It fixes roughly every problem that I’ve had with nix-shell, and does so in a much nicer way than my previous ad-hoc solutions.
– Ian Henry, https://ianthehenry.com/posts/how-to-learn-nix/nix-direnv/
9.9 Python
9.9.1 New virtual dev environment
pipenv install is your friend here.
New environment from an existing requirements.txt file:
pipenv --rm; pipenv install --python 3 --requirements requirements.txt
To install requirements for the particular project globally, you can use pipenv install --system.
9.9.2 Accepting input from stdin in Python
#!/usr/bin/env python3
class MyFilter:
@staticmethod
def filter() -> str:
"""
:arg stdio: Line with coordinates
:returns: File name
"""
import sys
for line in sys.stdin:
i = int(line)
process(i)
def process(line: str) -> str:
coordinates = line
name = fetch(coordinates)
return name9.9.3 Parallel execution
Parallel function execution can be done very elegantly with Ray as given below.
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))Source: Robert Nishihara, https://stackoverflow.com/a/48177988
9.9.4 Asynchronous programming
Be aware that running asynchronous functions in parralel is not the same as running code in different threads. While different threads will effectively run concurrently, asynchronous tasks run in an event loop will run one at a time, yield on blocking calls to let other tasks perform their duties and resume when on top of the loop again.
This means that only one function will be run at a time, even if you’ll have the actual impression of them being run in parralel.
– https://romain.dorgueil.net/blog/en/tips/2016/09/05/asynchronous-python-parralel.html
A simplified schematic of execution of such a sequence: Source: romain.dorgueil.net
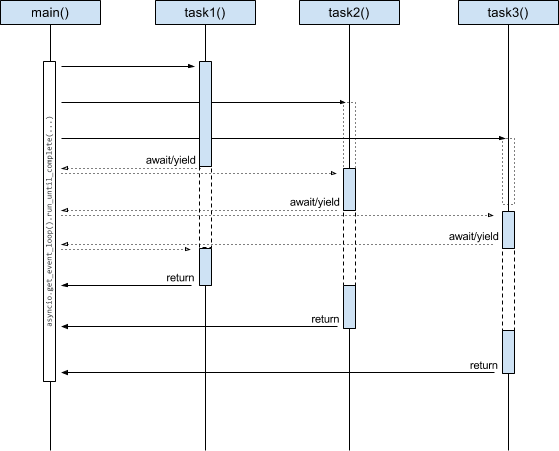{kind=link}
Python’s threads are not suitable for CPU-bound tasks, only for I/O-bound.
What do the terms “CPU bound” and “I/O bound” mean?
It’s pretty intuitive:
A program is CPU bound if it would go faster if the CPU were faster, i.e. it spends the majority of its time simply using the CPU (doing calculations). A program that computes new digits of pi will typically be CPU-bound, it’s just crunching numbers.
A program is I/O bound if it would go faster if the I/O subsystem was faster.
– User unwind, StackOverflow.com, https://stackoverflow.com/a/868577
async def main():
# run them sequentially (but the loop can do other stuff in the meanwhile)
body1 = await get_body('http://httpbin.org/ip')
print body1
body2 = await get_body('http://httpbin.org/user-agent')
print body2
# run them in parallel
task1 = get_body('http://httpbin.org/ip')
task2 = get_body('http://httpbin.org/user-agent')
for body in await asyncio.gather(task1, task2):
print(body)9.9.5 TDD
When we want to test a method that needs an external resource to function, it is easiest and fastest to test it in isolation. That is possible with the use of a technique called “assertion injection”.
The trick is to expose the resource-fetching function as an optional parameter of our function. Then, we can redefine the fetching function before executing our test.
The implementation would then be structured as in the below example.
from urllib.request import urlopen
class RemoteResource:
'Represents some sort of remotely-fetched resource'
server = 'example.com'
def __init__(self, rel_url, urlopen=urlopen):
'''rel_url is the HTTP URL of the resource, relative to the server
urlopen is the function to open the URL'''
url = 'http://{}/{}'.format(self.server, rel_url)
self.resource = urlopen(url)Test case:
import unittest
from rr import RemoteResource
class TestUrl(unittest.TestCase):
def test_build_url(self):
def myurlopen(url):
self.assertEqual('http://example.com/testpath.json', url)
rres = RemoteResource('testpath.json', myurlopen)Source: Aaron Maxwell, http://redsymbol.net/articles/assertion-injection/
9.10 System configuration management
9.10.1 Nix - Pure
Using Nix in our CI system has been a huge boon. Through Nix we have a level of guarantee of reproducibility between our local development environment and our CI platform.
‒ Fareed Zakaria, https://fzakaria.com/2021/09/10/using-an-overlay-filesystem-to-improve-nix-ci-builds.html
The latest and recommended version of Nix is 2.3.2. The quickest way to install
it on Linux and macOS is to run the following in a shell (as a user other than
root):
curl https://nixos.org/nix/install | shThe main problems with Nix:
- Does not work on MacOS (at least not on mine), and
- It is yet another tool to learn.
As someone summarized the 2nd point well:
I’ve been using Nix for a month and definitely the hardest part is that it’s a leaky abstraction. So if it works, setting up Nginx or RabbitMQ is as simple as writing
service.enable = true, and it’s truly magical.If something goes wrong, you have to understand: 1. Nix, 2. Nix abstraction on top of the service, 3. The service and how it’s configured, 4. Linux; it’s a lot to ask.
– myaccountonhn, https://news.ycombinator.com/item?id=39171614
9.10.2 Chef - Test-driven
Test-driven workstation configuration, no client-side software required: InSpec and Chef. See chef.io.
9.12 Docker
Alpine Linux — the base image of choice for a generation of Docker users — is essentially BusyBox plus musl libc plus apk. Around 5MB. The constraint aesthetic of a 1995 floppy became the constraint aesthetic of container registries. The problem changed; the solution held.
Every time you pull FROM alpine, you are running Perens’ 1995 insight at a planetary scale.
– Yair Etziony, https://www.linkedin.com/posts/yair-etziony_in-1995-bruce-perens-had-a-problem-debian-share-7436546718013480960-fw3M
9.12.1 Run builds in Docker as non-root
Problem: Build files from your Docker container are deletable only by root. Also, errors appear about the $HOME or $USER variables being unset.
Solution: Run builds as a normal user.
Sometimes you get a message like this:
Don't run this as root!This happens for example when trying to install Brew in a GitLab CI container.
The build may sometimes need to execute a root-level command, and it should not
need to ask for a password then. Therefore, the user should be able to run
sudo wihtout a password.
To do that, give an existing user in the image passwordless sudo rights, and run further commands as that user. Alternatively, create a new user and then give them passwordless sudo rights.
# Enable passwordless sudo for user named "user".
RUN echo "user ALL=(ALL) NOPASSWD:ALL" | tee --append /etc/sudoers
# Create the user (important to do *after* the previous step!).
RUN useradd --create-home user
# Run all further commands in the container as the newly created user.
USER user9.12.2 Review running containers
9.12.2.1 Docker built-in method
docker ps -a view is unclear due to long lines that do not wrap in a uniform
manner.
9.12.2.2 Vertical listing
To display all containers vertically, call the following script:
#!/usr/bin/env bash
export FORMAT="ID\t{{.ID}}\nNAME\t{{.Names}}\nIMAGE\t{{.Image}}\nPORTS\t{{.Ports}}\nCOMMAND\t{{.Command}}\nCREATED\t{{.CreatedAt}}\nSTATUS\t{{.Status}}\n"
docker ps --format="$FORMAT"9.12.2.3 Third-party terminal-based dashboard
An alternative is the dry monitoring tool.
9.12.3 Clean up
Remove all stopped Docker containers: docker ps -a -q | xargs docker rm -v.
Remove all unlabeled images not attach to any running container:
docker images -f dangling=true -q | xargs docker rmi.
If both Docker client and daemon APIs are of version at least 1.25, the command docker image prune can be used. Command reference: docker image prune | Docker Documentation.
9.12.4 History
As told by Mike Baukes from UpGuard, Inc.
LXC (LinuX Containers) is a OS-level virtualization technology that allows creation and running of multiple isolated Linux virtual environments (VE) on a single control host. These isolation levels or containers can be used to either sandbox specific applications, or to emulate an entirely new host. LXC uses Linux’s cgroups functionality, which was introduced in version 2.6.24 to allow the host CPU to better partition memory allocation into isolation levels called namespaces . Note that a VE is distinct from a virtual machine (VM), as we will see below.
Docker, previously called dotCloud, was started as a side project and only open-sourced in 2013. It is really an extension of LXC’s capabilities. This it achieves using a high-level API that provides a lightweight virtualization solution to run processes in isolation. Docker is developed in the Go language and utilizes LXC, cgroups, and the Linux kernel itself. Since it’s based on LXC, a Docker container does not include a separate operating system; instead it relies on the operating system’s own functionality as provided by the underlying infrastructure. So Docker acts as a portable container engine, packaging the application and all its dependencies in a virtual container that can run on any Linux server.
Source: Mike Baukes, UpGuard, February 12, 2020; https://www.upguard.com/articles/docker-vs-lxc
9.13 Machine Learning
Only when a model is fully integrated with the business systems, we can extract real value from its predictions.
– Soledad Galli and Christopher Samiullah, udemy.com
9.13.1 Track model versions: DVC (Data Version Control)
How does DVC compare to alternatives?
DVC seems to trump git-lfs in (…) [several] key ways. (…) Git-annex is more flexible, but more challenging to work with and configure. And both git-lfs and git-annex suffer from a final, major issue:
[they use] Git’s smudge and clean filters to show the real file on checkout. Git only stores that small text file and does so efficiently. The downside, of course, is that large files are not version controlled: only the latest version of a file is kept in the repository.
DVC offers a significant improvement in the following areas:
- Managing large datafiles in ML systems
- Effective reproducibility in ML systems
- Team onboarding and code sharing efficiency
- Reduction in tooling and hacking required for ML system cohesion
- Performing and tracking experiments
Source: Christopher G. Samiullah, christophergs.github.io
9.13.1.1 Installing DVC
Getting Started address: https://dvc.org/doc/get-started/agenda
9.14 Ghost
Back up an instance:
- Do an export of the content via GUI,
- Back up the
/content/imagesfolder (or the place you have configured to store images and other assets), - Back up your theme.
You can also use the Ghost Content API to make the backup.
Source: Ghost: Backup best practices
9.15 Haskell
9.15.1 Packaging
The *.cabal file is the package-level configuration. It can be generated by
hpack from a package.yaml. This configuration provides essential information
about the package: dependencies, exported components (libraries, executables,
test suites), and settings for the build process (preprocessors, custom
Setup.hs).
The stack.yaml file is the project-level configuration, which specifies a particular environment to make a build reproducible, pinning versions of compiler and dependencies. This is usually specified by a resolver (such as lts-11.4).
stack.yaml is not redundant with package.yaml. package.yaml specifies what dependencies are needed. stack.yaml indicates one way to consistently resolve dependencies (specific package version, and/or where to get it from, for example: on Hackage, a remote repository, or a local directory).
Source: https://stackoverflow.com/a/49776281
To load package version from a file in script mode, use:
import System.Environment
import System.Exit
import System.Process
import System.Environment.FindBin
import Data.Version (parseVersion)
-- | Get program location
--
-- Example:
--
-- >>> program_dir
-- "/home/user/package_example"
program_dir = getProgPath
-- | Read package version from file
--
-- Example:
--
-- >>> pkg_version "./package.yaml"
-- "0.2.4.0"
pkg_version :: String -> IO String
pkg_version file_name = do
contents <- readFile file_name
let version_line = lines contents !! 1
let version_word = words version_line !! 1
return version_word
-- | Get current package version
--
-- Example:
--
-- >>> version
-- "0.2.4.0"
show_version :: IO ()
show_version = do
location <- program_dir
version <- pkg_version $ location ++ "/package.yaml"
putStrLn $ version
main :: IO ()
main = show_version9.15.2 Getting started
Start out with GHC(I).
- Install Stack with GHCI.
- Use the following procedure to enter an REPL console.
-- GHCI configuration for Unicode support.
import Turtle
:set -XOverloadedStrings
-- Do not escape Unicode characters.
import Text.Show.Unicode
:set -interactive-print=Text.Show.Unicode.uprint9.15.3 IO
Haskell I/O has always been a source of confusion and surprises for new Haskellers. While simple I/O code in Haskell looks very similar to its equivalents in imperative languages, attempts to write somewhat more complex code often result in a total mess. This is because Haskell I/O is really very different internally. Haskell is a pure language and even the I/O system can’t break this purity.
– https://wiki.haskell.org/IO_inside
The following text is an attempt to explain the details of Haskell I/O implementations. This explanation should help you eventually master all the smart I/O tricks. Moreover, I’ve added a detailed explanation of various traps you might encounter along the way. After reading this text, you will receive a “Master of Haskell I/O” degree that is equal to a Bachelor in Computer Science and Mathematics, simultaneously.
9.15.4 TempateHaskell
TH is (…) outright dangerous:
- Code that runs at compile-time can do arbitrary
IO, including launching missiles or stealing your credit card. You don’t want to have to look through every cabal package you ever download in search for TH exploits.- TH can access “module-private” functions and definitions, completely breaking encapsulation in some cases.
– https://stackoverflow.com/questions/10857030/whats-so-bad-about-template-haskell
9.15.5 Practical use examples
- Sigma by Facebook,
- Haskell for supply chain optimization at Target,
- Functional Payout Framework at Barclays Bank,
- US government security system by Galois,
- “Trust your most critical systems” – Galois motto
- Cardano SL,
- Copilot project for NASA.
Source: https://serokell.io/blog/top-software-written-in-haskell
9.16 C++
9.16.1 Lint
clang-tidy 3.9 is the best C++ lint tool I’ve ever used in nearly twenty years of industrial experience. Bar none.
(tip: try clang-tidy -fix, it’ll auto rewrite your code to fix the lint problems. Doesn’t always get it right, plus it can eat your code so don’t run it unsupervised, but -fix is an amazing time saver).
Source: https://www.reddit.com/r/cpp/comments/5b397d/what_c_linter_do_you_use/
9.16.2 Run file as script
Add this as shebang:
//usr/bin/clang++ "$0" && exec ./a.out "$@"
Source: Pedro Lacerda, 2015, https://stackoverflow.com/questions/2482348/run-c-or-c-file-as-a-script
9.16.3 CMake
This tool is used to automate builds of C programs and the like. The tutorial
is available at https://cmake.org/cmake-tutorial/. To perform a build in a good
style, so called “out-of-source build”, in the project directory containing
CMakeLists.txt we issue mkdir build && cd build && cmake ... This way, all
output files land in the directory named build and the project itself is not
cluttered. This also means no make clean or the like is necessary.
For obtaining remote resources that the project is based on,
FetchContent_MakeAvailable may be helpful.
9.16.4 Tail-call optimization
All current mainstream compilers perform tail call optimisation fairly well (and have done for more than a decade), even for mutually recursive calls such as:
int bar(int, int);
int foo(int n, int acc) {
return (n == 0) ? acc : bar(n - 1, acc + 2);
}
int bar(int n, int acc) {
return (n == 0) ? acc : foo(n - 1, acc + 1);
}Credit: Konrad Rudolph, https://stackoverflow.com/a/34129
9.17 HTML
Adding a class name or ID to an element does nothing to that element by default.
This is something that snagged me as a beginner. You are working on one site and figure out that applying a particular class name fixes a problem you are having. Then you jump over to another site with the same problem and try to fix it with that same class name thinking the class name itself has some magical property to it only to find out it didn’t work.
Classes and ID’s don’t have any styling information to them all by themselves. They require CSS to target them and apply styling.
Source: https://css-tricks.com/the-difference-between-id-and-class/
9.18 JavaScript
9.18.1 Loading modules
Once a module has been loaded it won’t be reloaded if the require() call is run again.
By putting it inside a function instead of your top level module code, you can delay its loading or potentially avoid it if you never actually invoke that function.
However, require() is synchronous and loads the module from disk so best practice is to load any modules you need at application start before your application starts serving requests which then ensures that only asynchronous IO happens while your application is operational.
– https://stackoverflow.com/questions/9132772/lazy-loading-in-node-js
9.18.2 Writing reusable functions
Name all functions, including closures and callbacks. Avoid anonymous functions. This is especially useful when profiling a node app. Naming all functions will allow you to easily understand what you’re looking at when checking a memory snapshot.
Built-in doctests can help maintain reusability of functions in the file.
#!/usr/bin/env node
// Doctest the current file.
function test_units() {
const doctest = require('doctest');
doctest(process.argv[1], {module: 'commonjs', silent: true});
}
function decide_exit_code(results) {
for (let r of results) {
if (r[0] === false) {
// Test suite failed.
process.exit(1);
}
}
}
if ( require.main === module ) {
show_help();
test_units()
.then(decide_exit_code);
// After tests we can do something else.
//main();
}Clean code can be defined as code written in such a manner that is self-explanatory, easy to understand by humans and easy to change or extend.
Source: https://devinduct.com/blogpost/22/javascript-clean-code-best-practices
- Function arguments should be 2 or fewer, ideally.
- If more arguments needed, pass an object instead.
- Function should do one thing.
- Instead of checking in one function if a given client is active, and only then sending an e-mail to them, check if active in one function, and send in another.
- Function names should say what they do.
- Name
addToDateis better asaddMonthToDate.
- Name
- Functions should only be one level of abstraction.
- Function
parseBetterJSAlternativetaking tens of lines is better as several separate functions:tokenize,lexer, etc., sourcing data from each other.
- Function
- Remove duplicate code.
- Don’t use flags as function parameters.
- Flags tell your use that your function does more than one thing.
- Remove
if (flag) then (...) else (...)from functions into separater functions for each flag value. - Then, call the appropriate function when needed.
- Building a “library of one-level abstractions”.
Source: Beau Carnes, FreeCodeCamp, YT
Inspiration for the video above: Ryan McDermott, GitHub.com
“Even bad code can function. But if the code isn’t clean, it can bring a development organization to its knees.”
— Robert C. Martin (Uncle Bob), source: Blog.RisingStack.com
9.18.3 Promises
Unlike “old-style”, passed-in callbacks, a promise comes with some guarantees:
- Callbacks will never be called before the completion of the current run of the JavaScript event loop.
- Callbacks added with then() even after the success or failure of the asynchronous operation, will be called, as above.
- Multiple callbacks may be added by calling then() several times. Each callback is executed one after another, in the order in which they were inserted.
One of the great things about using promises is chaining.
Promise usage example:
doSomething()
.then(function(result) {
return doSomethingElse(result);
})
.then(function(newResult) {
return doThirdThing(newResult);
})
.then(function(finalResult) {
console.log('Got the final result: ' + finalResult);
})
.catch(failureCallback);Can that be made shorter? Yes, it can!
doSomething()
.then(result => doSomethingElse(result))
.then(newResult => doThirdThing(newResult))
.then(finalResult => {
console.log(`Got the final result: ${finalResult}`);
})
.catch(failureCallback);Important: We should always return results, otherwise callbacks won’t catch the result of a previous promise (with arrow functions () => x is short for () => { return x; }).
Basically, a promise chain stops if there’s an exception, looking down the chain for catch handlers instead. This is very much modeled after how synchronous code works:
doSomething()
.then(result => doSomethingElse(result))
.then(newResult => doThirdThing(newResult))
.then(finalResult => console.log(`Got the final result: ${finalResult}`))
.catch(failureCallback);This symmetry with asynchronous code culminates in the async/await
syntactic sugar in ECMAScript 2017:
async function foo() {
try {
const result = await doSomething();
const newResult = await doSomethingElse(result);
const finalResult = await doThirdThing(newResult);
console.log(`Got the final result: ${finalResult}`);
} catch(error) {
failureCallback(error);
}
}Promises solve a fundamental flaw with the callback pyramid of doom, by catching all errors, even thrown exceptions and programming errors. This is essential for functional composition of asynchronous operations.
Await only blocks the code execution within the async function. It only makes sure that next line is executed when the promise resolves.
If your code contains blocking code it is better to make it an async function. By doing this you are making sure that somebody else can use your function asynchronously.
When using async -> await make sure to use try catch for error handling.
Sources:
9.18.4 Composing your software
Be stateless, kill your servers almost every day.
– NodeJS best practices, user goldbergyoni, github.com
<!-- index.html -->
<!DOCTYPE html>
<html lang="en" style="height: 100%;">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, initial-scale=1">
<title>Boilerplate</title>
<link rel="stylesheet" href="scripts/lib/another_lib.css">
<script src="scripts/lib/another_lib.js"></script>
<script src="scripts/lib/jquery.js"></script>
</head>
<body style="margin: 0; height: 100%">
<div id="map" style="height: 100%"></div>
<script type="module" src="./main.js"></script>
</body>
</html>// main.js
"use strict";
import {clean_map} from
'./scripts/clean_map.js';
import {add_marker} from
'./scripts/add_marker.js';
// After this function invocation, the map being displayed should already have
// the desired properties, like displaying the correct content and doing it in
// the declared style.
function transform(map) {
map = add_marker(map);
return map;
}
transform(clean_map());// scripts/module.js
"use strict";
function add_marker(map) {
// (...)
return map;
}
export {add_marker};There is also the JavaScript Module Pattern described for example here or here.
9.18.5 Managing depencencies
Monorepos [come] with multiple packages, each containing a package.json file. If you’d like to install dependencies for all of them with npm, that would include going over each directory and issuing npm install in all of them.
To help with this process, yarn introduced workspaces. In combination with Lerna, it gives package authors a powerful toolset to manage the dependencies and of projects and also enables publishing to be a lot easier.
– https://blog.risingstack.com/yarn-vs-npm-node-js-package-managers/
Lerna is a tool that optimizes the workflow around managing multi-package repositories with git and npm. Internally it uses Yarn or the npm CLI to bootstrap (i.e. install all third party dependencies for each package) a project. In a nutshell, Lerna calls yarn/npm install for each package inside the project and then creates symlinks between the packages that refer each other.
(…)
Lerna calls yarn install multiple times for each package which creates overhead because each package.json is considered independent and they can’t share dependencies with each other.
– https://yarnpkg.com/blog/2017/08/02/introducing-workspaces/
To initialize a workspace, we can use a package.json file like below.
{
"private": true,
"workspaces": ["workspace-a", "workspace-b"]
}Note that private: true is required. “workspace-a” and “workspace-b” are names of directories where the respective sub-packages reside. Each of those packages can be then required by another, and to do so we should use the contents of the package.json -> name field, even (especially!) if that name differs from the name of the package directory.
Yarn’s workspaces are the low-level primitives that tools like Lerna can (and do!) use. They will never try to support the high-level feature that Lerna offers, but by implementing the core logic of the resolution and linking steps inside Yarn itself we hope to enable new usages and improve performance.
9.18.7 Test headlessly
For testing JavaScript for the Web, a headless browser is very handy. Firefox can be run in headless mode with the -headless switch (sic. - single dash).
Socket.IO can be used to transmit a message and receive the message in Bash via NodeJS.
#!/usr/bin/env bash
# linger_and_browse shell script
browser() {
firefox -headless localhost:3000
}
wait_till_available() {
nmap localhost | grep 3000
if [[ "$?" -eq 0 ]]; then
browser
else
sleep 1 && wait_till_available
fi
}
linger_and_browse() {
echo "Waiting until port 3000 becomes open..."
wait_till_available
}
linger_and_browseAn exemplary test suite is shown below for use with BATS.
#!/usr/bin/env bats
# Update stream test suite.
setup() {
./configure preconfigure
}
teardown() {
./configure restore
}
@test "Should send a message, receive reception confirmation and exit." {
run ./linger_and_browse &
run node index.js
[[ $status == 0 ]]
}To enable a script to close the Firefox window for the time of testing, we can use the following script.
#!/usr/bin/env bash
# configure shell script
provide_deps() {
sudo apt install -y firefox
}
preconfigure() {
#
# If the file exists, we abort the operation.
if [[ -f "$HOME/.mozilla/firefox/*.default/user.js" ]]; then
exit -1
fi
cd ~/.mozilla/firefox/*.default
#cd *.default
echo 'user_pref("dom.allow_scripts_to_close_windows", true);' >> user.js
}
restore() {
#
# We simply remove the last line from the file.
sed -i '$ d' ~/.mozilla/firefox/*.default/user.js
}
"$@"The main file for NodeJS is given below.
var app = require('express')();
var http = require('http').createServer(app);
var io = require('socket.io')(http);
app.get('/', function(req, res){
res.sendFile(__dirname + '/index.html');
});
function message_cb(msg) {
console.log('message: ' + msg);
if (msg == 'Thanks!') {
io.emit('chat message', msg);
return process.exit(0);
}
}
function disconnect_cb() {
console.log('user disconnected');
}
function connection_cb(socket) {
console.log('a user connected');
// let msg = "Welcome to the room, Listener!"
let msg = "Welcome!"
io.emit('chat message', msg);
socket.on('chat message', message_cb);
socket.on('disconnect', disconnect_cb);
}
io.on('connection', connection_cb);
http.listen(3000, function(){
console.log('listening on *:3000');
});The test runner in HTML in index.html is exemplified below.
<!doctype html>
<html>
<head>
<title>Socket.IO chat</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body { font: 13px Helvetica, Arial; }
form { background: #000; padding: 3px; position: fixed; bottom: 0; width: 100%; }
form input { border: 0; padding: 10px; width: 90%; margin-right: .5%; }
form button { width: 9%; background: rgb(130, 224, 255); border: none; padding: 10px; }
#messages { list-style-type: none; margin: 0; padding: 0; }
#messages li { padding: 5px 10px; }
#messages li:nth-child(odd) { background: #eee; }
</style>
<script src="/socket.io/socket.io.js"></script>
<script src="https://code.jquery.com/jquery-1.11.1.js"></script>
<script>
$(function () {
var socket = io();
$('form').submit(function(e){
e.preventDefault(); // Prevents page reloading.
socket.emit('chat message', $('#m').val());
$('#m').val('');
return false;
});
socket.on('chat message', function(msg){
$('#messages').append($('<li>').text(msg));
if (msg == 'Welcome!') {
socket.emit('chat message', 'Thanks!');
window.open('','_self').close();
} else {
socket.emit('chat message', $('#m').val());
}
});
});
</script>
</head>
<body>
<ul id="messages"></ul>
<form action="">
<input id="m" autocomplete="off" /><button>Send</button>
</form>
</body>
</html>9.18.8 Track events in Web JS functions from Bash
It is not simple to display a message in the console when something happens in the JavaScript console. However, with Socket.IO it is possible to event events from localhost and receive them on localhost as well. It works on port 3000.
A tutorial is available at https://socket.io/get-started/chat.
A preview:
$ make
Waiting until port 3000 becomes open...
listening on *:3000
3000/tcp open ppp
a user connected
a user connected
message: abcd
message: Hi! This is your browser applet!// index.js
var app = require('express')();
var http = require('http').createServer(app);
var io = require('socket.io')(http);
app.get('/', function(req, res){
res.sendFile(__dirname + '/index.html');
});
function connection_cb(socket) {
console.log('a user connected');
socket.on('chat message', function(msg){
console.log('message: ' + msg);
});
socket.on('disconnect', function() {
console.log('user disconnected');
});
}
io.on('connection', connection_cb);
http.listen(3000, function(){
console.log('listening on *:3000');
});The main HTML file:
<!-- index.html -->
<!doctype html>
<html>
<head>
<title>Socket.IO chat</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body { font: 13px Helvetica, Arial; }
form { background: #000; padding: 3px; position: fixed; bottom: 0; width: 100%; }
form input { border: 0; padding: 10px; width: 90%; margin-right: .5%; }
form button { width: 9%; background: rgb(130, 224, 255); border: none; padding: 10px; }
#messages { list-style-type: none; margin: 0; padding: 0; }
#messages li { padding: 5px 10px; }
#messages li:nth-child(odd) { background: #eee; }
</style>
<script src="/socket.io/socket.io.js"></script>
<script src="https://code.jquery.com/jquery-1.11.1.js"></script>
<script>
$(function () {
var socket = io();
$('form').submit(function(e){
e.preventDefault();
socket.emit('chat message', $('#m').val());
$('#m').val('');
return false;
});
});
</script>
</head>
<body>
<ul id="messages"></ul>
<form action="">
<input id="m" autocomplete="off" /><button>Send</button>
</form>
</body>
</html>#!/usr/bin/env bash
# browse: a script for Bash.
browser() {
firefox localhost:3000
}
wait_till_available() {
nmap localhost | grep 3000
if [[ "$?" -eq 0 ]]; then
browser
else
sleep 1 && wait_till_available
fi
}
echo "Waiting until port 3000 becomes open..."
wait_till_available9.18.9 Preview JSON data
9.18.9.1 View online
JSON Editor Online displays your JSON side-by-side in a readable, hierarchical format.
9.18.10 Tweak code performance
Tweak software performance using “wormholes”: see DZone
9.18.11 Authenticate clients to a server
A less-well-known but useful feature of SSL is that it can be used to authenticate clients to a server, as well as simply providing an encrypted communication channel.
– Laurence Withers
Examples of how a client can be authenticated to a server include:
- SQRL by Gibson Research Corporation,
- SSL, see
9.19 Embedded devices
9.19.1 Connect with a device via UART
Default command to connect with the main UART device: minicom -b 115200 -o -D /dev/ttyUSB0.
9.19.2 Write image to an SD card
#!/usr/bin/env bash
# Write image to SD card.
default_image=ubuntu-18.04.1-preinstalled-server-armhf+raspi2.img.xz
# Use the default image or the given one.
image=${1-$default_image}
xzcat "$image" | sudo dd bs=4M status=progress of=/dev/mmcblk09.19.4 Generate a true random number
Some chips, like STM32-F303R8 29, feature a “true generator of random numbers”.
How to use such a generator?
The chip does not have a hardware RNG.
But you can roll your own. The usual approach is to measure jitter between INDEPENDENT clocks. Independent means that the two clocks are backed by different christals or RC-oscillators and not derived from the same.
I would use:
- SysTick timer / counter derived from system clock (MHz range)
- One of the kHz-range RC oscillators
Set up a counter on the kHz-range RC oscillator to give you an interrupt several times a second. In the interrupt handler you read the current value of the SysTick counter. Whether or not SysTick is used for other purposes (scheduling), the lower 5 or so bits are by all means unpredictable.
For getting random numbers out of this, use a normal pseudo RNG. Use the entropy gathered above to unpredictably mutate the internal state of the pseudo RNG. For key generation, don’t read all the bits at once but allow for a couple of mutations to happen.
Attacks against this are obvious: If the attacker can measure or control the kHz-range RC oscillator up to MHz precision, the randomness goes away. If you are worried about that, use a smart card or other security co-processor.
‒ Edgar Holleis 30
https://www.hashicorp.com/resources/cloudinit-the-good-parts↩︎
Documentation sources](https://kali.training/topic/documentation-sources/).↩︎
Steve Kemp, Dupes in Sysadmin Utils↩︎
https://www.schibsted.pl/blog/devops/securing-data-with-git-crypt/↩︎
https://botland.com.pl/pl/stm32-nucleo/7607-stm32-nucleo-l432kc-stm32l432kcu6-arm-cortex-m4.html?search_query=nucleo&results=40↩︎